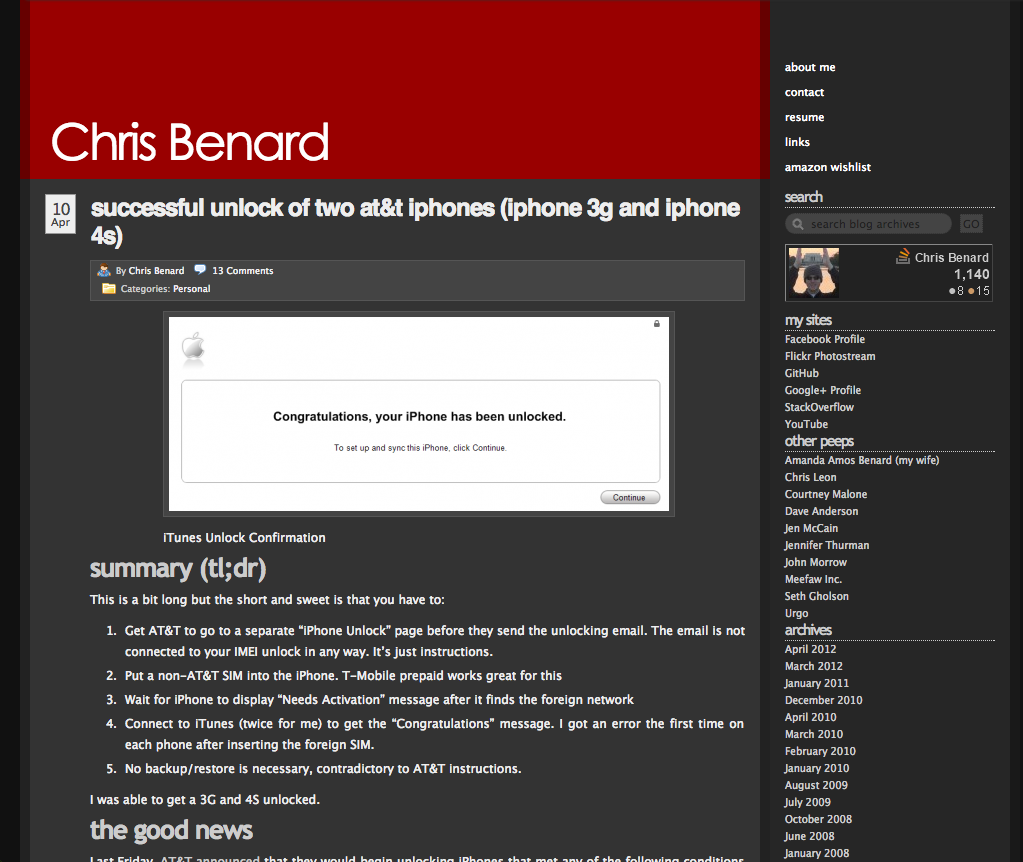
Extract Text from RTF in C#/.Net
At work, I was tasked with creating a class to strip RTF tags from RTF formatted text, leaving only the plain text. Microsoft’s RichTextBox can do this with its Text property, but it was unavailable in the context in which I’m working.
RTF formatting uses control characters escaped with backslashes along with nested curly braces. Unfortunately, the nesting means I can’t kill the control characters using a single regex, since I’d have to process the stack, and in addition, some control characters should be translated, such as newline and tab characters.
Example:
{\rtf1\ansi\deff0
{\colortbl;\red0\green0\blue0;\red255\green0\blue0;}
This line is the default color\line
\cf2
This line is red\line
\cf1
This line is the default color
}
Thankfully, Markus Jarderot provided a great answer over at StackOverflow, but unfortunately for me, it’s written in Python. I don’t know Python, but I translated it to the best of my abilities to C# since it was very readable.
If this is useful to you, you can download the C# version, or view the original/new code below.
The code in this post is licensed Creative Commons Attribution-ShareAlike 3.0 Unported (CC BY-SA 3.0), as is all code on Stack Overflow.
View Original Python Code
def striprtf(text):
pattern = re.compile(r"\\([a-z]{1,32})(-?\d{1,10})?[ ]?|\\'([0-9a-f]{2})|\\([^a-z])|([{}])|[\r\n]+|(.)", re.I)
# control words which specify a "destionation".
destinations = frozenset((
'aftncn','aftnsep','aftnsepc','annotation','atnauthor','atndate','atnicn','atnid',
'atnparent','atnref','atntime','atrfend','atrfstart','author','background',
'bkmkend','bkmkstart','blipuid','buptim','category','colorschememapping',
'colortbl','comment','company','creatim','datafield','datastore','defchp','defpap',
'do','doccomm','docvar','dptxbxtext','ebcend','ebcstart','factoidname','falt',
'fchars','ffdeftext','ffentrymcr','ffexitmcr','ffformat','ffhelptext','ffl',
'ffname','ffstattext','field','file','filetbl','fldinst','fldrslt','fldtype',
'fname','fontemb','fontfile','fonttbl','footer','footerf','footerl','footerr',
'footnote','formfield','ftncn','ftnsep','ftnsepc','g','generator','gridtbl',
'header','headerf','headerl','headerr','hl','hlfr','hlinkbase','hlloc','hlsrc',
'hsv','htmltag','info','keycode','keywords','latentstyles','lchars','levelnumbers',
'leveltext','lfolevel','linkval','list','listlevel','listname','listoverride',
'listoverridetable','listpicture','liststylename','listtable','listtext',
'lsdlockedexcept','macc','maccPr','mailmerge','maln','malnScr','manager','margPr',
'mbar','mbarPr','mbaseJc','mbegChr','mborderBox','mborderBoxPr','mbox','mboxPr',
'mchr','mcount','mctrlPr','md','mdeg','mdegHide','mden','mdiff','mdPr','me',
'mendChr','meqArr','meqArrPr','mf','mfName','mfPr','mfunc','mfuncPr','mgroupChr',
'mgroupChrPr','mgrow','mhideBot','mhideLeft','mhideRight','mhideTop','mhtmltag',
'mlim','mlimloc','mlimlow','mlimlowPr','mlimupp','mlimuppPr','mm','mmaddfieldname',
'mmath','mmathPict','mmathPr','mmaxdist','mmc','mmcJc','mmconnectstr',
'mmconnectstrdata','mmcPr','mmcs','mmdatasource','mmheadersource','mmmailsubject',
'mmodso','mmodsofilter','mmodsofldmpdata','mmodsomappedname','mmodsoname',
'mmodsorecipdata','mmodsosort','mmodsosrc','mmodsotable','mmodsoudl',
'mmodsoudldata','mmodsouniquetag','mmPr','mmquery','mmr','mnary','mnaryPr',
'mnoBreak','mnum','mobjDist','moMath','moMathPara','moMathParaPr','mopEmu',
'mphant','mphantPr','mplcHide','mpos','mr','mrad','mradPr','mrPr','msepChr',
'mshow','mshp','msPre','msPrePr','msSub','msSubPr','msSubSup','msSubSupPr','msSup',
'msSupPr','mstrikeBLTR','mstrikeH','mstrikeTLBR','mstrikeV','msub','msubHide',
'msup','msupHide','mtransp','mtype','mvertJc','mvfmf','mvfml','mvtof','mvtol',
'mzeroAsc','mzeroDesc','mzeroWid','nesttableprops','nextfile','nonesttables',
'objalias','objclass','objdata','object','objname','objsect','objtime','oldcprops',
'oldpprops','oldsprops','oldtprops','oleclsid','operator','panose','password',
'passwordhash','pgp','pgptbl','picprop','pict','pn','pnseclvl','pntext','pntxta',
'pntxtb','printim','private','propname','protend','protstart','protusertbl','pxe',
'result','revtbl','revtim','rsidtbl','rxe','shp','shpgrp','shpinst',
'shppict','shprslt','shptxt','sn','sp','staticval','stylesheet','subject','sv',
'svb','tc','template','themedata','title','txe','ud','upr','userprops',
'wgrffmtfilter','windowcaption','writereservation','writereservhash','xe','xform',
'xmlattrname','xmlattrvalue','xmlclose','xmlname','xmlnstbl',
'xmlopen',
))
# Translation of some special characters.
specialchars = {
'par': '\n',
'sect': '\n\n',
'page': '\n\n',
'line': '\n',
'tab': '\t',
'emdash': u'\u2014',
'endash': u'\u2013',
'emspace': u'\u2003',
'enspace': u'\u2002',
'qmspace': u'\u2005',
'bullet': u'\u2022',
'lquote': u'\u2018',
'rquote': u'\u2019',
'ldblquote': u'\201C',
'rdblquote': u'\u201D',
}
stack = []
ignorable = False # Whether this group (and all inside it) are "ignorable".
ucskip = 1 # Number of ASCII characters to skip after a unicode character.
curskip = 0 # Number of ASCII characters left to skip
out = [] # Output buffer.
for match in pattern.finditer(text):
word,arg,hex,char,brace,tchar = match.groups()
if brace:
curskip = 0
if brace == '{':
# Push state
stack.append((ucskip,ignorable))
elif brace == '}':
# Pop state
ucskip,ignorable = stack.pop()
elif char: # \x (not a letter)
curskip = 0
if char == '~':
if not ignorable:
out.append(u'\xA0')
elif char in '{}\\':
if not ignorable:
out.append(char)
elif char == '*':
ignorable = True
elif word: # \foo
curskip = 0
if word in destinations:
ignorable = True
elif ignorable:
pass
elif word in specialchars:
out.append(specialchars[word])
elif word == 'uc':
ucskip = int(arg)
elif word == 'u':
c = int(arg)
if c < 0: c += 0x10000
if c > 127: out.append(unichr(c))
else: out.append(chr(c))
curskip = ucskip
elif hex: # \'xx
if curskip > 0:
curskip -= 1
elif not ignorable:
c = int(hex,16)
if c > 127: out.append(unichr(c))
else: out.append(chr(c))
elif tchar:
if curskip > 0:
curskip -= 1
elif not ignorable:
out.append(tchar)
return ''.join(out)
View Translated C# Code
/// <summary>
/// Rich Text Stripper
/// </summary>
/// <remarks>
/// Translated from Python located at:
/// http://stackoverflow.com/a/188877/448
/// </remarks>
public static class RichTextStripper
{
private class StackEntry
{
public int NumberOfCharactersToSkip { get; set; }
public bool Ignorable { get; set; }
public StackEntry(int numberOfCharactersToSkip, bool ignorable)
{
NumberOfCharactersToSkip = numberOfCharactersToSkip;
Ignorable = ignorable;
}
}
private static readonly Regex _rtfRegex = new Regex(@"\\([a-z]{1,32})(-?\d{1,10})?[ ]?|\\'([0-9a-f]{2})|\\([^a-z])|([{}])|[\r\n]+|(.)", RegexOptions.Singleline | RegexOptions.IgnoreCase);
private static readonly List<string> destinations = new List<string>
{
"aftncn","aftnsep","aftnsepc","annotation","atnauthor","atndate","atnicn","atnid",
"atnparent","atnref","atntime","atrfend","atrfstart","author","background",
"bkmkend","bkmkstart","blipuid","buptim","category","colorschememapping",
"colortbl","comment","company","creatim","datafield","datastore","defchp","defpap",
"do","doccomm","docvar","dptxbxtext","ebcend","ebcstart","factoidname","falt",
"fchars","ffdeftext","ffentrymcr","ffexitmcr","ffformat","ffhelptext","ffl",
"ffname","ffstattext","field","file","filetbl","fldinst","fldrslt","fldtype",
"fname","fontemb","fontfile","fonttbl","footer","footerf","footerl","footerr",
"footnote","formfield","ftncn","ftnsep","ftnsepc","g","generator","gridtbl",
"header","headerf","headerl","headerr","hl","hlfr","hlinkbase","hlloc","hlsrc",
"hsv","htmltag","info","keycode","keywords","latentstyles","lchars","levelnumbers",
"leveltext","lfolevel","linkval","list","listlevel","listname","listoverride",
"listoverridetable","listpicture","liststylename","listtable","listtext",
"lsdlockedexcept","macc","maccPr","mailmerge","maln","malnScr","manager","margPr",
"mbar","mbarPr","mbaseJc","mbegChr","mborderBox","mborderBoxPr","mbox","mboxPr",
"mchr","mcount","mctrlPr","md","mdeg","mdegHide","mden","mdiff","mdPr","me",
"mendChr","meqArr","meqArrPr","mf","mfName","mfPr","mfunc","mfuncPr","mgroupChr",
"mgroupChrPr","mgrow","mhideBot","mhideLeft","mhideRight","mhideTop","mhtmltag",
"mlim","mlimloc","mlimlow","mlimlowPr","mlimupp","mlimuppPr","mm","mmaddfieldname",
"mmath","mmathPict","mmathPr","mmaxdist","mmc","mmcJc","mmconnectstr",
"mmconnectstrdata","mmcPr","mmcs","mmdatasource","mmheadersource","mmmailsubject",
"mmodso","mmodsofilter","mmodsofldmpdata","mmodsomappedname","mmodsoname",
"mmodsorecipdata","mmodsosort","mmodsosrc","mmodsotable","mmodsoudl",
"mmodsoudldata","mmodsouniquetag","mmPr","mmquery","mmr","mnary","mnaryPr",
"mnoBreak","mnum","mobjDist","moMath","moMathPara","moMathParaPr","mopEmu",
"mphant","mphantPr","mplcHide","mpos","mr","mrad","mradPr","mrPr","msepChr",
"mshow","mshp","msPre","msPrePr","msSub","msSubPr","msSubSup","msSubSupPr","msSup",
"msSupPr","mstrikeBLTR","mstrikeH","mstrikeTLBR","mstrikeV","msub","msubHide",
"msup","msupHide","mtransp","mtype","mvertJc","mvfmf","mvfml","mvtof","mvtol",
"mzeroAsc","mzeroDesc","mzeroWid","nesttableprops","nextfile","nonesttables",
"objalias","objclass","objdata","object","objname","objsect","objtime","oldcprops",
"oldpprops","oldsprops","oldtprops","oleclsid","operator","panose","password",
"passwordhash","pgp","pgptbl","picprop","pict","pn","pnseclvl","pntext","pntxta",
"pntxtb","printim","private","propname","protend","protstart","protusertbl","pxe",
"result","revtbl","revtim","rsidtbl","rxe","shp","shpgrp","shpinst",
"shppict","shprslt","shptxt","sn","sp","staticval","stylesheet","subject","sv",
"svb","tc","template","themedata","title","txe","ud","upr","userprops",
"wgrffmtfilter","windowcaption","writereservation","writereservhash","xe","xform",
"xmlattrname","xmlattrvalue","xmlclose","xmlname","xmlnstbl",
"xmlopen"
};
private static readonly Dictionary<string, string> specialCharacters = new Dictionary<string, string>
{
{ "par", "\n" },
{ "sect", "\n\n" },
{ "page", "\n\n" },
{ "line", "\n" },
{ "tab", "\t" },
{ "emdash", "\u2014" },
{ "endash", "\u2013" },
{ "emspace", "\u2003" },
{ "enspace", "\u2002" },
{ "qmspace", "\u2005" },
{ "bullet", "\u2022" },
{ "lquote", "\u2018" },
{ "rquote", "\u2019" },
{ "ldblquote", "\u201C" },
{ "rdblquote", "\u201D" },
};
/// <summary>
/// Strip RTF Tags from RTF Text
/// </summary>
/// <param name="inputRtf">RTF formatted text</param>
/// <returns>Plain text from RTF</returns>
public static string StripRichTextFormat(string inputRtf)
{
if (inputRtf == null)
{
return null;
}
string returnString;
var stack = new Stack<StackEntry>();
bool ignorable = false; // Whether this group (and all inside it) are "ignorable".
int ucskip = 1; // Number of ASCII characters to skip after a unicode character.
int curskip = 0; // Number of ASCII characters left to skip
var outList = new List<string>(); // Output buffer.
Match match = _rtfRegex.Match(inputRtf);
if (!match.Success)
{
// Didn't match the regex
return inputRtf;
}
while (match.Success)
{
string word = match.Groups[1].Value;
string arg = match.Groups[2].Value;
string hex = match.Groups[3].Value;
string character = match.Groups[4].Value;
string brace = match.Groups[5].Value;
string tchar = match.Groups[6].Value;
if (!String.IsNullOrEmpty(brace))
{
curskip = 0;
if (brace == "{")
{
// Push state
stack.Push(new StackEntry(ucskip, ignorable));
}
else if (brace == "}")
{
// Pop state
StackEntry entry = stack.Pop();
ucskip = entry.NumberOfCharactersToSkip;
ignorable = entry.Ignorable;
}
}
else if (!String.IsNullOrEmpty(character)) // \x (not a letter)
{
curskip = 0;
if (character == "~")
{
if (!ignorable)
{
outList.Add("\xA0");
}
}
else if ("{}\\".Contains(character))
{
if (!ignorable)
{
outList.Add(character);
}
}
else if (character == "*")
{
ignorable = true;
}
}
else if (!String.IsNullOrEmpty(word)) // \foo
{
curskip = 0;
if (destinations.Contains(word))
{
ignorable = true;
}
else if (ignorable)
{
}
else if (specialCharacters.ContainsKey(word))
{
outList.Add(specialCharacters[word]);
}
else if (word == "uc")
{
ucskip = Int32.Parse(arg);
}
else if (word == "u")
{
int c = Int32.Parse(arg);
if (c < 0)
{
c += 0x10000;
}
outList.Add(Char.ConvertFromUtf32(c));
curskip = ucskip;
}
}
else if (!String.IsNullOrEmpty(hex)) // \'xx
{
if (curskip > 0)
{
curskip -= 1;
}
else if (!ignorable)
{
int c = Int32.Parse(hex, System.Globalization.NumberStyles.HexNumber);
outList.Add(Char.ConvertFromUtf32(c));
}
}
else if (!String.IsNullOrEmpty(tchar))
{
if (curskip > 0)
{
curskip -= 1;
}
else if (!ignorable)
{
outList.Add(tchar);
}
}
// Get the next match
match = match.NextMatch();
}
returnString = String.Join(String.Empty, outList.ToArray());
return returnString;
}
}
Update: Johnny Lie pointed out some important performance improvements that I have incorporated. Instead of loading all the regex matches, it iterates through them one by one now. This allows larger regex to be processed successfully. Additionally, I have clarified the code license as CC BY-SA 3.0, due to the origin code coming from Stack Overflow, thanks to a comment by Spencer Schneidenbach.